Данный обзор подготовлен по заказу редакции журнала «625» для № 8'2006 ( www.625-net.ru)
Дисковые системы хранения
Немного истории
Идея объединения нескольких сравнительно дешевых жестких дисков в одно логическое устройство с целью повышения общей емкости, быстродействия и надежности была высказана еще в конце 80-х годов прошлого века. Более точно, впервые публично она была изложена в 1987 году в ставшей с тех пор классической статье калифорнийского университета Беркли под названием « A Case for Redundant Arrays of Inexpensive Disks ( RAID )”. Но до недавнего времени подобные системы, получившие название RAID -массивов, в основном были частью очень дорогостоящих компьютерных комплексов, предназначенных для хранения больших объемов критически важной информации (в качестве типичного примера обычно приводят банковские серверы). Проблема состояла в том, что для обеспечения действительно надежной и эффективной работы RAID -систем, отвечающих предъявляемым к ним требованиям, приходилась использовать не дешевые, а напротив, дорогостоящие дисковые устройства (именно поэтому впоследствии термин RAID стали «расшифровывать» как Redundant Arrays of Independent Discs ). И только сейчас, когда за счет общего прогресса стоимость таких решений значительно упала, и появились достаточно хорошие диски по разумной цене, различные решения на базе RAID технологии стали активно предлагаться для рабочих станций и серверов, а в упрощенном варианте - для офисных и даже домашних компьютеров.
Впрочем, стоимость внешних RAID -систем снижается не так быстро, как цены на базовые диски – последние определяют лишь «половину» затрат на создание полной системы. Весьма существенную ее часть составляют специализированный контроллер (со встроенным процессором) и программное обеспечение ( firmware ), собственно и обеспечивающие совместную эффективную работу дисков как единого целого. Более того, в полном соответствии с пословицей, что аппетит приходит во время еды, по мере развития технологий пропорционально растут требования к характеристикам систем. Сегодня пользователи желают получить массивы емкостью в 3-6 терабайт (системы в 10 и более ТБ тоже возможны уже сейчас) со скоростью записи/чтения в сотни мегабайт в секунду. Соответственно производители отвечают на это все более мощными решениями, использующими последние модели RISC -процессоров. Так что стоимость «современных» RAID -систем, как и ранее, остается на уровне от нескольких тысяч долларов до десятков тысяч. Оно и понятно – в компьютерной индустрии, так же как и в других отраслях высоких технологий, действует общий «закон» сохранения стоимости (иначе ее развитие прекратится). Но «за те же деньги» пользователь сегодня получает в несколько раз более мощную систему, чем еще несколько лет назад.
В России и сторически так сложилось, что одними из наиболее активных потребителей подобных систем стали видеостудии и телецентры. Причина очевидна – цифровой кино/видео материал требует таких больших объемов дисковой памяти и таких высоких скоростей записи/чтения данных, что без специализированных дисковых систем хранения (внешних массивов) во многих случаях было бы просто невозможно работать над сложными проектами. В качестве характерного приложения можно привести задачу цифрового видеомонтажа. Сегодня здесь на повестке дня одновременная обработка в реальном времени трех-четырех потоков некомпрессированного видео и нескольких слоев графики и титров. При стандартном разрешении телевизионного кадра 720 x 576 и YUV представлении 4:2:2 это требует скоростей воспроизведения до 80-90 Мбайт/сек, при этом необходимая для хранения всего десяти часов видео емкость составляет около терабайта. С другой стороны, все более актуальными становятся различные системы HD монтажа, оперирующие с телевизионными кадрами высокой четкости 1280 x 720 25 p или даже 1920х1080 50 i . Соответственно требования к объемам и потокам возрастают в разы. Впрочем, надо оговориться, что на практике при работе в HD разрешении пока сдерживают потребности за счет разумного использования различных кодеков и оперируют компрессированными потоками порядка 100 Мбит/сек.
Способы организации хранения
Напомним, что первоначально видеомонтажные рабочие станции строились по
классическому принципу самодостаточности – мощная вычислительная база сочеталась в одном корпусе с многодисковой подсистемой памяти. И если для установки операционной системы и размещения различных программ-приложений обычно использовались сравнительно доступные по цене IDE диски, то для хранения и обработки собственно видеоматериала рекомендовалось устанавливать дорогие, но «быстрые» и надежные SCSI диски. По мере развития и усложнения решаемых задач увеличивалось количество рабочих мест, покупались новые более производительные машины соответственно с более емкими подсистемами хранения. Со временем в студии возникал своеобразный зоопарк компьютеров разных моделей, разной производительности и соответственно разных возможностей. Каждая рабочая станция на момент покупки стоила немалых денег – и поразительно быстро устаревала, при этом переход со старой машины на новую, перенос программного обеспечения и данных был весьма трудоемок и длителен. Именно поэтому «простая» идея «отвязать» хотя бы дисковую память от конкретной станции (сервера), замена которой в случае необходимости наращивания вычислительных мощностей оказывалась более простой задачей, сразу привлекла внимание IT -руководителей студий.
Так лет пять назад в нашу жизнь вошли DAS ( D irect A ttached S torage ) системы – независимые дисковые системы хранения, напрямую подключаемые к рабочим станциям и серверам по SCSI интерфейсу. Конструктивно это RAID -массивы на 4-16 дисков в отдельном корпусе со своим процессором и оперативной памятью, надежным (избыточным) питанием и охлаждением, встроенной системой управления и самодиагностики. Несмотря на сложную внутреннюю организацию компьютерами они видятся как обычные SCSI устройства (вчера это был Ultra 160 SCSI , сегодня Ultra 320, а завтра уже ожидается повсеместный переход на SAS – Serial Attached SCSI ). А поскольку любой более-менее сложный проект предполагает групповую работу над одним и тем же материалом, то рабочие станции и обычные офисные компьютеры объединяются в локальную Ethernet сеть. В результате схема построения общей сети студии выглядит следующим образом:
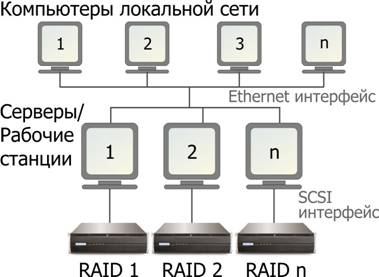
Оказалось, что пока объем общих данных невелик, а число рабочих станций (серверов) не превышает 2-3, такая классическая архитектура построения вычислительной сети вполне удовлетворяет реальным потребностям студии. Однако, по мере ее развития, приобретения под новые задачи дополнительных станций (опять же со своими RAID массивами) и соответствующего роста объема данных даже гигабитная сеть не справляется с пересылаемыми потоками и регулярно становится узким местом, существенно снижающим общую производительность. Более того, в последнее время в связи с резким ростом объемов производства отечественной кино и видеопродукции, и особенно с многократным увеличением числа телевизионных сериалов, особую остроту приобрела проблема эффективной обработки исходного видеоматериала последовательно несколькими специалистами. Пересаживать их с одной рабочей станции на другую? Перегонять рабочий материал по сети (а это терабайты)? Или даже переносить (если не перевозить) DAS систему хранения (от 15 до 40 килограмм ) от одного компьютера к другому? Все эти способы известны из практики, но они только увеличивают время и сложность работы над проектом.
Выход - в использовании преимуществ Fibre Channel интерфейса и построении на его основе специализированной сети только для передачи данных между рабочими станциями (серверами), отделив ее от локальной сети прочих пользователей. Fibre Channel ( FC ) существует довольно давно, но всегда считался уделом только очень богатых организаций с «неограниченными» бюджетами, особо не обращающими внимание на цену вопроса. С тех времен многое изменилось, но большинство ИТ специалистов до сих пор помнят о невероятной стоимости решений на базе FC и по инерции даже не предполагают возможность его применения у себя.
Между тем это не просто обычный интерфейс между двумя устройствами. Очень упрощенно его идею можно изложить так: высокоскоростная передача потоков данных (подобно SCSI ) по последовательным каналам с возможностью коммутации и маршрутизации (подобно обычным Ethernet сетям) и работой на больших расстояниях (до десятков километров). Физическая реализация канала может быть и на основе медного кабеля (но с существенными ограничениями ограничением по скорости и дальности), однако в основном используется оптоволокно (с дальность работы до 300 метров на оптических многомодовых кабелях для 2 GB варианта, 150 метров для 4 GB варианта и полной скорости интерфейса, до 10 километров на одномодовых кабелях). Скорости передачи данных по стандарту - 1 Гбит/сек, 2 Гбит/сек и 4 Гбит/сек. C учетом того, что для соединения устройств применяются два оптических кабеля, каждый из которых работает в одном направлении, при сбалансированном наборе операций записи/чтения скорость обмена данными удваивается, т.е. Fibre Channel работает в полнодуплексном режиме. В пересчете на мегабайты паспортная скорость составляет соответственно 100, 200 и 400 Мбайт/сек. Реально при 50% соотношении операций записи/чтения скорость интерфейса достигает уже 200 Мбайт/сек, 400 Мбайт/сек и 800 Мбайт/сек. В будущем должны появиться варианты на 10 Гбит/сек (или 1000 Мбайт/сек). Сегодня наиболее популярны решения на 2 Гбит/сек, поскольку они имеют лучшее соотношение цена/качество. Но с этой осени уже реальными становятся устройства на 4 Гбит/сек.
Топология FC напоминает сетевую – это может быть и последовательное соединение устройств в кольцо (петля с арбитражем), и точка-точка соединение (в результате практически ничем не отличается от SCSI, разве что расстояния между устройствами могут быть на порядки больше). Но самая популярная и перспективная топология Fibre Channel – это подключение через коммутируемую матрицу, Switched Fabric (также иногда используют название переключаемая матрица) . Несмотря на определенную функциональную схожесть с хабом или маршрутизатором обычного Ethernet, FC матрица принципиально от них отличается по производительности. Через нее различные устройства одновременно и параллельно работают на полной скорости, нисколько не мешая друг другу, как если бы они были соединены друг с другом напрямую. Современные Switched Fabric, такие как QLogic SANBox 5600 на 16 FC портов, имеют агрегированную полосу пропускания 144 Гбит/сек, т.е. 16 портов на 4+4 Гбит/сек плюс полоса, необходимая для каскадирования (подключения к другой Switched Fabric). Таким образом, применение FС дает возможность принципиально изменить архитектуру компьютерной сети любой организации.
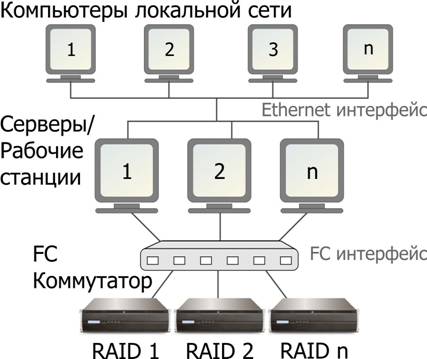
В этом варианте возможности по конфигурированию огромны – любая станция (сервер) может обращаться к любому, разрешенному администратором системы дисковому ресурсу. Более того, возможен доступ к одному и тому же диску нескольких устройств одновременно, причем с высокой скоростью, не идущей ни в какое сравнение со скоростью передачи данных по Ethernet. И что особенно важно – будущее наращивание и масштабирование вычислительных средств студии перестает быть головоломной задачей. В зависимости от того, нехватка каких возможностей возникла, достаточно добавить либо новую рабочую станцию либо новую систему хранения, подключив их к сети через FC коммутатор-матрицу. При таком построении отпадают и проблемы «переноса» данных с одного рабочего места на другое. По завершении очередного этапа работы над фильмом другой сотрудник сразу начинает заниматься тем же самым фильмом, никуда не перемещая файлы и нисколько не теряя в скорости доступа к данным. Более того, вполне возможна и одновременная работа нескольких пользователей над одним проектом, что существенно ускоряет производственный процесс. Фактически, все подключенные таким образом дисковые массивы при использовании специального программного обеспечения образуют единую совместную систему хранения студии. Эта прогрессивная технология получила название SAN ( S torage A rea N etwork, сеть систем хранения).
Таковы основные преимущества использования FC сетей в видеопроизводстве. Однако есть еще одна серьезная причина для перехода на FC - устранение шума из видеомонтажной. Современные системы хранения данных включают в себя, как правило, до 16 жестких дисков, несколько блоков питания и вентиляторов охлаждения. Все это техническое великолепие, увы, шумит - и шумит заметно. Для людей, занимающихся творчеством с утра до вечера, этот шум является весьма серьезной проблемой. Применение же Fibre Channel позволяет ликвидировать ее как класс. Допустимого расстояния в сотни метров в любом здании с лихвой хватит для удаления рабочих компьютеров от систем хранения ( SAN сети).
Единственный недостаток FC – сравнительно высокая стоимость оборудования (особенно коммутаторов). Но, во-первых, в последнее время благодаря увеличивающейся популярности цены стали заметно снижаться. И главное, начальные затраты для развивающихся компаний быстро окупаются за счет более высокой производительности (отдачи с рабочего места) и существенной экономии на последующем расширении. Хотя надо признать, что применение Fibre Channel для малых студий на две-три рабочих станций (сервера) все еще экономически неоправданно. И для них пока более разумным остается классическая DAS архитектура. Впрочем, для хранения общих (архивных) данных студии вне зависимости от ее размера целесообразно использование специальных сетевых устройств хранения, так называемых NAS устройств ( Network Attached Storage ).
Сетевые устройства хранения ( NAS)
До недавнего времени для хранения в локальной сети и совместной работы с общими данными, как правило, опять же закупались довольно дорогие сервера с требуемой дисковой емкостью (так называемые файловые сервера). Причем на эти сервера, как правило, ставилась операционная система Windows , а сами они требовали соответствующего внимания системных администраторов и регулярного обслуживания. Но зачем так дорого и сложно, если такой сервер выполняет только сравнительно несложные задачи по отправке и получению данных? Действительно, когда сервера используются в основном для организации хранения, то полезная загрузка установленных процессоров крайне незначительна, да и оперативной памяти немного требуется. Но при этом, как это ни смешно, большие ресурсы уходят на поддержку функционирования собственно операционной системы. В результате несколько лет назад появились особые устройства, которые официально называются NAS ( N etwork A ttached S torage – сетевое устройство хранения), или упрощенно готовые файловые сервера.
Идея NAS довольно проста – фактически это обычный компьютер (чаще всего используются недорогие процессоры AMD или Intel Celeron ) с прошитой в памяти операционной системой (обычно это какой-либо клон Linux ). Но «прошиваются» только те части операционной системы, которые предназначены для обслуживания всех функций NAS , поэтому объем такой операционной системы не превышает 32 мегабайт. Поддерживаются различные RAID уровни хранения данных, но опять же программно. Из того, что операционная система «зашита» в ПЗУ, вытекает весьма важная особенность NAS – его крайне трудно «взломать» снаружи. Такая оптимизация операционной системы исключительно под нужды файлового сервера приводит к высокому быстродействию и надежности NAS , даже, несмотря на программную организацию RAID .
В результате в локальную сеть предприятия (студии) включаются выделенные устройства хранения данных общего назначения (нередко архивных), которые записываются-считываются по мере потребности.
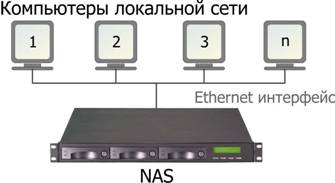
Надо особо подчеркнуть, что основное назначение NAS устройств, это хранение готовых данных, копирование и архивирование материалов, созданных на рабочих станциях, да и обмен данными между ними - через NAS . Однако попытки использовать любые сетевые устройства для размещения промежуточных материалов в процессе их создания, для удаленного редактирования видео даже с DV качеством, как правило, оказываются разочаровывающими. Хотя э лементарные расчеты убедительно показывают, что вроде бы все должно получиться. Реальная полоса гигабитной сети 60-70 мегабайт в секунду и ее должно хватить чуть ли не на 20 DV потоков, по 3,5 мегабайт в секунду. Иными словами, по идее до 20 человек вроде могут одновременно смотреть и редактировать DV видео в реальном времени (если конечно имеющаяся рабочая станция + видеомонтажная программа позволяют) без каких-либо проблем. Сказано – сделано, и ряд студий попытались внедрить у себя подобную технологию. Однако результат оказался плачевным - не то что 20, даже 5 человек не могли одновременно комфортно работать с видео даже DV качества. И вроде бы все правильно, да и формально то все работает, но вот производительность труда, если можно так выразиться, никакая. Поскольку эта ошибка регулярно допускается в различных студиях, то на причинах данного «парадокса» стоит остановиться подробнее.
Суть проблемы в том, что не учитывается тот простой факт, что для комфортной работы с видео пропускная способность канала "видеоредактор – данные в сети" должна быть не меньше канала "локальный диск - программа". Но, кроме поддержки высокой средней скорости потока данных, и время реакции системы на каждый запрос данных от пользователя должно быть не больше привычного, то есть как от локального жесткого диска (или напрямую подключенного к станции RAID массива). В противном случае любой человек немедленно почувствует заметные задержки в системе, причем в первую очередь в ее откликах на свои команды - а это и есть дискомфорт.
Что же происходит, когда данные находятся в сети, а не на локальном диске? Полоса пропускания в сети делится между пользователями и время реакции на запрос видеомонтажной программы может увеличиться в разы по сравнению с локальным диском. В результате все очень просто - программа начинает обработку, посылает запрос на необходимые данные, который ставится в очередь – и далее ей приходится относительно долго (по сравнению с локальным диском) ждать запрошенных данных. Задержка особенно заметна в случае, когда рабочая станция обрабатывает кадры быстрее реального времени (т.е. на просчет измененного кадра уходит меньше 20 мс). Разница между работой с локальным диском (под локальным диском здесь и далее мы будем понимать любой локальный диск, локальный RAID массив и т.п.) и работой по сети будет тем больше, чем мощнее рабочая станция и чем быстрее ее локальный диск. Пропускная способность сети фактор постоянный, так что работа с данными по сети фактически снижает эффективную производительность собственно рабочей станции. Если же скорость падает на порядок, когда в сети одновременно пытаются работать более пяти монтажеров, то работа становится просто невыносимой.
К сожалению, в рамках гигабитного Ethernet ничего сделать нельзя. Возможно, светлое будущее за 10-гигабитным Ethernet и реализацией iSCSI. Но когда наступит это светлое будущее, когда это оборудование станет доступным и коммерчески обоснованным, сказать сложно. Что делать сейчас? Ответ уже был дан – использовать FC оборудование и строить выделенные сети хранения ( SAN ).
Больше, быстрее, надежнее
Напомним, что основные задачи, которые призван решить RAID массив как система объединения нескольких дисков в одно логическое устройство, это увеличение емкости, скорости записи/чтения и повышение надежности хранения данных. С емкостью все понятно – чем больше используется составляющих систему дисков и чем больше емкость каждого из них, тем лучше. Сегодня Seagate уже предлагает SATA диски емкостью 750 GB . Таким образом, для популярного 16 дискового массива доступная емкость может составлять 12 Терабайт!
Особое внимание уделяется задаче обеспечения надежности хранения данных. Она решается как на аппаратном уровне (избыточные блоки питания и вентиляторы охлаждения, выделение нескольких дисков для «горячего» резервирования, возможность установки специального модуля с батареей-аккумулятором для сохранения данных кэш-памяти при аварийном отключении питания), так и программном (интеллектуальная система самодиагностики дисков, контроля напряжения и температуры). Эффективным средством защиты данных является выбор RAID уровня, обеспечивающего необходимый компромисс между эффективностью работы массива (доступный объем и быстродействие) и его надежностью хранения (допустимым числом отказавших дисков).
В современных дисковых массивах используются специализированные контроллеры, построенные на базе высокопроизводительных RISC процессоров, аппаратно поддерживающие следующие RAID уровни.
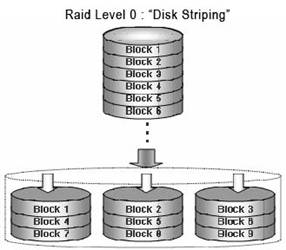
RAID 0 – простое распараллеливание, веерная запись/чтение блоками на все установленные диски. Самая высокая производительность, минимальная цена на гигабайт хранения, но отсутствие защиты от сбоя. Поскольку RAID 0 определяет простейший вариант построения массива - без избыточности дисков, то, строго говоря, он даже не является RAID . Тем не менее, этот уровень официально утвержден консорциумом по стандартизации RAID ( RAID Advisory Board , RAB ) и широко используется на практике.
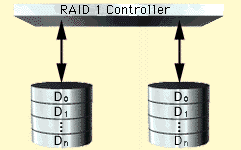
RAID 1- зеркалирование, т.е. дублирование всех записей на две идентичные группы дисков. Обеспечивается самая высокая степень защиты критически важных данных, но как следствие - вдвое меньший доступный объем хранения.
RAID 3 – входной поток данных разбивается на блоки, по всем битам которых вычисляются контрольные значения четности. Запись/чтение осуществляется параллельно на все диски, но при этом для контрольных данных выделяется отдельный диск. При сохранении высокого быстродействия (сравнимого с RAID 0) данные не теряются при выходе из строя одного (любого) из дисков.
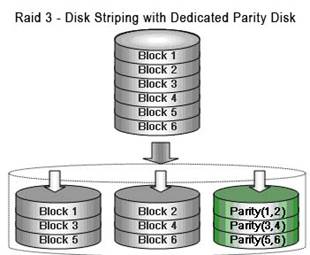
Данный уровень показывает хорошее быстродействие при чтении/записи больших файлов, что характерно для различных задач обработки видео. Однако в приложениях, характеризующихся большой интенсивностью коротких запросов эффективная скорость быстро падает. В частности, это обусловлено хранением всей резервной информации только на одном выделенном диске, то он становится «узким» местом - все последующие запросы ждут завершения обработки предыдущего.
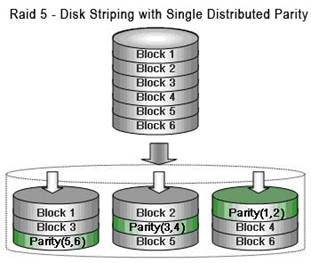
RAID 5 – аналогичен RAID 3, но запись значений четности распределена между всеми дисками. Кроме того, уменьшен размер блоков записываемых данных, что увеличивает быстродействие системы при большом количестве запросов на запись/чтение небольших файлов.
RAID 0+1, 30 (3+0), 50 (5+0) - это комбинированные варианты, в которых роль отдельных дисков играют RAID массивы соответственно 0, 3 или 5 уровня.
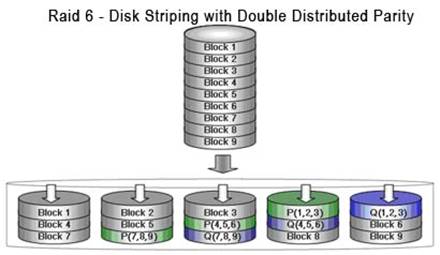
В RAID контроллерах последнего поколения, построенных в частности на базе процессора Intel i 80331, аппаратно реализованы более сложные уровни. RAID 6 – здесь параллельно рассчитываются 2 независимых значения четности, которые распределяются между всеми дисками. Сохранность данных обеспечивается при выходе из строя даже 2-х дисков.
Triple Parity ( TP ) – его еще называют RAID 6+. Три независимых значения четности, допустим одновременный выход 3-х дисков.
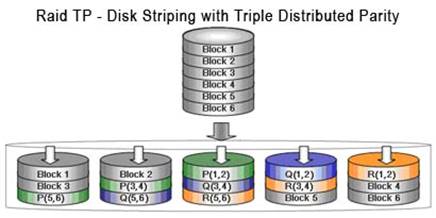
Впрочем, надо признать, что эти уровни вычислительно очень затратные, так что реальное быстродействие заметно ниже чем в 3 или 5 уровнях.
Все это позволяет сохранить данные даже при физическом повреждении работающего в системе диска (одного или нескольких). Однако доводить систему до такого критического состояния не стоит. Более благоразумно и грамотно предвидеть угрозу, заранее «вычислить» потенциально плохой диск (лучше еще до установки в систему) и принять превентивные меры к его замене. Именно для этого некоторые производители современных дисковых массивов предлагают для своих систем различные способы оперативной диагностики состояния дисков, что создает дополнительный «эшелон» защиты данных.
Впрочем, более правильным является не борьба со сбоями, а использование изначально более надежных дисков. На первый взгляд задача выбора дисков тривиальна – ценой поменьше, а объемом побольше.
Диски для RAID массивов
Несмотря на все хитроумные способы организации записи/чтения данных надежность хранения в первую очередь зависит от стабильности работы используемых в системе жестких дисков. Чаще всего в RAID-массивы без всякой задней мысли устанавливают стандартные диски, изначально предназначенные для обычных компьютеров. Они обладают большой емкостью, высокой надежностью и сравнительно низкой стоимостью. Казалось бы, чего же боле? Однако здесь и существует проблема!
Дело в том, что во все современные IDE/SATA жесткие диски для повышения надежности хранения данных встроена автоматическая функция коррекции ошибок. При ее разработке исходили из здравого посыла, что жесткий диск не должен отправлять куда-либо сообщение о каждой обнаруженной ошибке чтения, загружая тем самым другие устройства (в том числе процессор компьютера) ненужной дополнительной работой. Напротив, он должен предпринять все возможное для самостоятельной коррекции обнаруженной ошибки, для начала многократно пытаясь прочитать сбойный блок, а потом исключив его из использования, сделав переназначение (remap) плохого сектора на хороший. Погрузившись в данную "внутреннюю" операцию, диск начинает отвечать на внешние запросы с большой задержкой, тем большей, чем интенсивней поступают на него команды записи/чтения. И это правильно до тех пор, пока этот диск функционирует сам по себе, являясь самостоятельным, не входящим ни в какие RAID массивы, устройством хранения данных. Однако когда он является частью сложной системы из многих дисков в RAID массиве, некоторые диски в которых выделены для хранения резервных данных на случай любой ошибки, т.е. системы, управляемой специализированным интеллектуальным RAID контроллером, подобная "самостоятельность" установленного в систему диска может приводить к проблемам.
Одной из важнейших задач аппаратного контроллера RAID является постоянный анализ распределяемых между дисками данных на предмет возможного появления и немедленной коррекции ошибок. Поэтому RAID контроллер, отвечая за работоспособность всей системы, ожидает ответа от каждого диска строго определенное время (обычно не более 8 секунд), по истечении которого считает, что вовремя не ответивший диск неисправен, и принимает решение об его исключении из системы с последующим перераспределением данных между оставшимися дисками. При этом нагрузка на них возрастает, и в этих условиях и второй диск может вовремя не ответить, что уже приведет к крушению всей системы с потерей данных (напомним, что в наиболее популярных RAID уровнях 3 и 5 резервные данные хранятся только на одном диске и выход сразу двух фатален - все данные теряются).
Причем в результате последующего анализа может оказаться, что отключенные диски были вполне работоспособны и могли далее использоваться, но уже будет слишком поздно. Здесь не поможет и наличие диска в "горячем" резерве - пока RAID контроллер будет вводить его в массив (этот процесс может занять часы и дни, в зависимости от нагрузки на RAID), вполне может "отвалиться" следующий диск в массиве и данные также будут безвозвратно потеряны. Эта ситуация иллюстрируется на рисунке ниже.

Безусловно, такая проблема возникает только при интенсивной работе дисков в RAID массиве на запись/чтение данных. Но достаточно совпадения буквально минутной "тяжелой" нагрузки на RAID массив и начала автоматической процедуры восстановления ошибки на каком-то жестком диске, как ложный выход из строя жесткого диска станет вполне реальным. Трудность решения этой проблемы в том, что диск и на самом деле, реально, может выйти из строя, поэтому увеличение допустимого времени отклика от жесткого диска, что иногда, к сожалению, делают некоторые производители RAID контроллеров не решает проблему, а наоборот, загоняет ее вглубь. Ведь в том случае, если диск на самом деле сломался, промедление в реакции RAID контроллера на это событие чревато полной потерей данных. Такие случаи, к сожалению, происходили не раз. И потерявшие все результаты месяца напряженной работы «творцы» кусали локти и проклинали производителей и поставщиков ненадежного оборудования. А заодно вообще всех «железячников». Но так ли они были виноваты?
Наличие данной проблемы (задержка отклика из-за встроенной функции коррекции ошибок) не зависит от того, диски или массив какого производителя вы планируете использовать. Ее возможное решение в другом – ввести ограничение на максимально допустимую длительность обработки ошибок жестким диском с обязательным информированием RAID контроллера о наличии конкретной ошибки. В этом случае RAID контроллер поймет, что диск исправен, но у него есть конкретная ошибка в конкретном месте, которую контроллер легко скорректирует.
Первой компанией, которая предложила такое понятное и очевидное любому грамотному специалисту решение, стала Western Digital Corporation. Она разработала специальную серию дисков RAID Edition ( RE ) c функцией TLER ( T ime L imited E rror C orrection - ограниченное время на коррекцию ошибки). TLER -диски при возникновении ошибки начинают нормальный процесс ее коррекции, но, не уложившись в 7 секунд, сообщают RAID-контроллеру о возникшей ошибке, откладывая дальнейшую обработку ошибки на "лучшее" время (например, на момент простоя системы). При этом контроллер легко справится с возникшей ошибкой чтения данных с данного диска – ведь для этого в его распоряжении всегда есть резервная информация. Такой алгоритм иллюстрируется на рисунке ниже.

Отметим, что RE диски от Western Digital кроме функции TLER отличает и увеличенное вдвое время наработки на отказ. Значение этого параметра, известного как MTBF (Mean Time Between Failure – среднее время между отказами), приводят все производители жестких дисков как важнейшую характеристику своей продукции. Конечно, сведений о корреляции MTBF с реальной статистикой отказов нет – и его значение напоминает среднюю температуру по больнице. Однако понятно, что чем MTBF больше, тем диски должны быть надежнее. Для обычных SATA дисков MTBF не превышает 500 000 часов. Для более дорогих SCSI дисков этот показатель уже равен 1 200 000 часов. У SATA дисков RAID Edition от Western Digital первого поколения, выпущенных в середине 2004 года, значение MTBF составляло 1 000 000 часов, а для поставляемых ныне R E дисков второго поколения ( RE 2) MTBF уже заявлено в 1 200 000 часов (более 100 лет непрерывной работы)! Дополнительным аргументом в польку SATA дисков WD RE является тот факт, что они официально предназначены для круглосуточной работы 24/7 в RAID массивах, а фирменная гарантия на них составляет 5 лет. При этом цена таких дисков превышает обычную не более чем на 10-15%, что практически незаметно на общей стоимости дисковой системы хранения данных. В связи с этим настоятельно рекомендуется использовать именно такие диски. Единственное существующее ограничение заключается в том, что пока максимальная емкость RE дисков ограничена 500ГБ. Впрочем, использование 750ГБ дисков от Seagate в дисковых системах хранения пока не очень разумно в силу новизны и неотработанности используемой в них технологии перпендикулярной записи.
Важным вопросом является видимый объем построенного RAID массива. Очевидно, что за исключением простейшего уровня RAID 0 доступная емкость отличается от суммы емкостей установленных в систему дисков, так как часть дисков «уходит» под резервные данные. В RAID 1 (зеркалирование) «теряется» ровно половина, в RAID 3 и 5 – один диск, в 6 уровне – 2, в 6+ - три диска. Кроме того, при хранении важных данных рекомендуется один из установленных дисков использовать под горячий резерв ( hot spare ) – в этом случае при выходе любого из рабочих дисков система автоматически его отключит и осуществит перенос (восстановление) данных на этот резервный диск. В качестве пояснения рассмотрим пример системы на 16 дисков по 500ГБ каждый. Простейший расчет показывает, что при RAID 0 доступный объем составит 8ТБ, RAID 1 - 4ТБ, RAID 3/5 – 7,5ТБ, RAID 6 – 7ТБ, ТР – 6,5ТБ. Ну и RAID 3/5 c одним диском в горячем резерве – 7ТБ.
Наконец рассмотрим вопрос о быстродействии дисковой системы хранения. Как же не раз подчеркивалось, для управления работой массива применяется специализированный RISC процессор с оперативной памятью (от 256 мегабайт) и внутренней шиной PCI-X. Повторимся, что с точки зрения компьютера, к которому подключается такая система хранения данных, это обычное SCSI устройство, поддерживающее все возможности SCSI интерфейса. Но поступающий от компьютера поток данных распределяется между всеми установленными в систему рабочими жесткими дисками. И при малом числе дисков быстродействие растет почти линейным образом пропорционально их числу. Добавляя все больше и больше дисков, можно тем самым увеличивать производительность, но только до тех пор, пока процессор системы хранения данных будет успевать обслуживать каждый диск без малейших задержек. Как только процессор перестанет успевать, дальнейшее увеличение количества дисков не приведет к увеличению производительности. Так вот, лучшие на середину 2006 года недорогие системы хранения данных на SATA дисках с процессором Intel 80331 667 MHz достигли максимальной скорости линейного чтения по тестам 270 мегабайт/сек, что близко к пропускной способности SCSI интерфейса (320 Мбайт/сек). В то же время теоретическая п олоса пропускания для 4 Gb Fibre Channel составляет 400 мегабайт в секунду в одну сторон (и столько же обратно), что с лихвой хватит для подавляющего большинства задач. А если не хватит, то применение технологии M ultipath позволяет еще удвоить полосу пропускания и получить результат, полностью перекрывающий все потребности на ближайшие годы.
В заключение добавим, что всегда актуальный вопрос выбора оптимального по соотношению цена/качество устройства хранения – это во многом вопрос выбора производителя и поставщика. В силу унификации компьютерной техники в большинстве случаев на аппаратном уровне подобные устройства отличаются только лейблом и ценой. Успехов вам!